
Go语言爬虫(三)
Go语言爬取网站图片
作为一个死宅,想找好看的图片,而且我几天换一张壁纸,最近缺少新的图片了,就去某乎找网站,下图是发现的网站,里面有大量好看的图片,就想爬下来慢慢挑
https://wall.alphacoders.com/tags.php?tid=229

步骤
1.分析每一页的url,每页变化的只有后面的数字,修改数字就可
https://wall.alphacoders.com/by_category.php?id=3&name=Anime+Wallpapers
https://wall.alphacoders.com/by_category.php?id=3&name=Anime+Wallpapers&page=2
https://wall.alphacoders.com/by_category.php?id=3&name=Anime+Wallpapers&page=3
2.分析每个小图的url,在如下第一张图中提取数字,改变第二张图url地址中的数字,即可
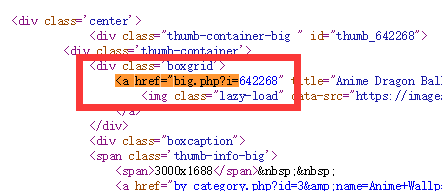

3.如图,进入url后不仅有大图,还有其他信息,所以需要找出大图的地址
<img class="main-content" src="https://images6.alphacoders.com/642/thumb-1920-642268.jpg"
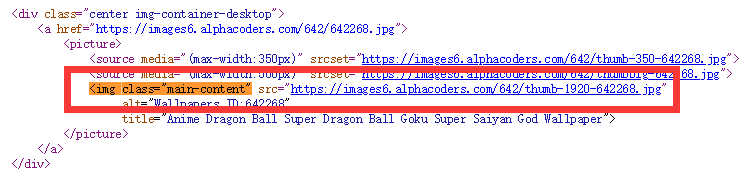
4.有了大图地址,就可以把整个信息保存成.jpg格式就行了

代码
package main
import (
"fmt"
"io"
"math/rand"
"net/http"
"os"
"regexp"
"strconv"
"time"
)
//获取一个网页所有的内容
func HttpGet(url string)(result string,err error){
resp ,err1 :=http.Get(url)
if err1!=nil{
err=err1
return
}
defer resp.Body.Close()
buf := make([]byte,4096)
for {
n,err2 :=resp.Body.Read(buf)
if n==0{
break
}
if err2!=nil&&err2!=io.EOF{
err =err2
return
}
result +=string(buf[:n])
}
return
}
//写入文件
func SaveJokeFile(url string){
//保存图片的名字是随机的6个数字
rand.Seed(time.Now().UnixNano())
var captcha string
for i := 0; i < 6; i++ {
//产生0到9的整数
num := rand.Intn(10)
//将整数转为字符串
captcha += strconv.Itoa(num)
}
//保存在本地的地址
path :="D:/Go code/src/Gopa/09爬图片/imgs/"+captcha+"张.jpg"
f,err :=os.Create(path)
if err!=nil{
fmt.Println("HttpGet err:",err)
return
}
defer f.Close()
//读取url的信息
resp,err := http.Get(url)
if err!=nil{
fmt.Println("http err:",err)
return
}
defer f.Close()
buf :=make([]byte,4096)
for{
n,err2 :=resp.Body.Read(buf)
if n==0{
break
}
if err2!=nil&&err2!=io.EOF{
err = err2
return
}
//写入文件
f.Write(buf[:n])
}
}
func working( start,end int){
fmt.Printf("正在爬取 %d 到 %d \n",start,end)
page :=make(chan int) //设置多线程
for i:=start;i<=end;i++{
go SpidePage(i,page)
}
for i:=start;i<=end;i++{
fmt.Printf("第 %d 页爬取完毕\n",<-page)
}
}
func main() {
//指定爬取起始、终止页
var start,end int
fmt.Println("请输入爬取的起始页(>=1):")
fmt.Scan(&start)
fmt.Println("请输入爬取的终止页(>=start):")
fmt.Scan(&end)
working(start,end)
}
func SpidePage(i int,page chan int){
//网站每一页的改变
url :="https://wall.alphacoders.com/by_category.php?id=3&name=Anime+Wallpapers&page="+strconv.Itoa(i*1)
//读取这个页面的所有信息
result,err :=HttpGet(url)
//判断是否出错,并打印信息
if err!=nil{
fmt.Println("SpidePage err:",err)
}
//正则表达式提取信息
str :=`<div class="thumb-container-big " id="thumb_(?s:(.*?))">`
//解析、编译正则
ret :=regexp.MustCompile(str)
//提取需要信息-每一个图片的数字
urls :=ret.FindAllStringSubmatch(result,-1)
for _,jokeURL := range urls{
//组合每个图片的url
joke :=`https://wall.alphacoders.com/big.php?i=`+jokeURL[1]
//爬取图片的url
tuUrl,err :=SpideJokePage(joke)
if err!=nil{
fmt.Println("tuUrl err:",err)
continue
}
SaveJokeFile(tuUrl)
}
//防止主go程提前结束
page <-i
}
//爬取图片放大的页面
func SpideJokePage(url string) (tuUrl string,err error){
//爬取网站的信息
result,err1 :=HttpGet(url)
if err1!=nil{
err = err1
fmt.Println("SpidePage err:",err)
}
str :=`<img class="main-content" src="(?s:(.*?))"`
//解析、编译正则
ret :=regexp.MustCompile(str)
//提取需要信息-每一个段子的url
alls :=ret.FindAllStringSubmatch(result,-1)
for _,temTitle :=range alls{
tuUrl = temTitle[1]
break
}
return
}
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 时间海!


评论





