
Go语言爬虫(二)
双向爬取:
- 横向:以页为单位。
- 纵向:以一个页面内的条目为单位
横向
横向的规律是itype在变化
https://v.qq.com/channel/cartoon?channel=cartoon&iarea=1&itype=2&listpage=1&sort=18
https://v.qq.com/channel/cartoon?channel=cartoon&iarea=1&itype=5&listpage=1&sort=18
纵向
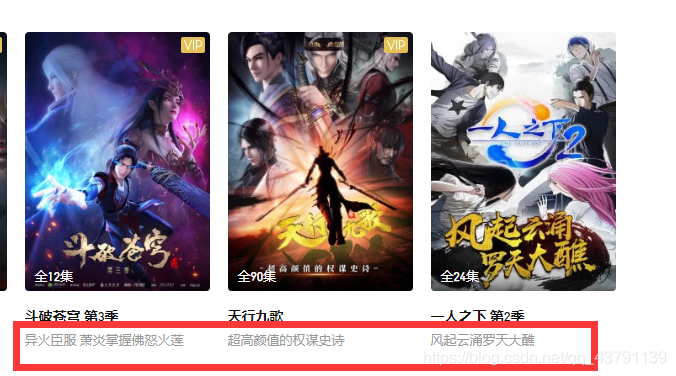
用正则表达式对下面进行分割
更新到第几集: `<div class="figure_caption" >全90集</div>`
动漫名称:target="_blank" title="天行九歌"
动漫介绍:<div class="figure_desc" title="超高颜值的权谋史诗">
`<div class="figure_caption" >(?s:(.*?))</div>`
`target="_blank" title="(?s:(.*?))"`
`<div class="figure_desc" title="(?s:(.*?))">`
实现流程
- 获取用户输入起始和终止、启动working函数循环调用SpiderPage(url)爬取每一个页面
- SpiderPage中,获取动漫信息 横向爬取url信息,封装HttpGet函数,爬取每一个页面所有数据 存入 result 返回
- 找寻、探索豆瓣网页 纵向爬取规律。找出 ”更新到第几集“ ”动漫名称“ ”动漫介绍“
- 分别对这三个数据使用go正则函数
- 将提取的数据,按自定义格式写入文件。使用 网页编号命名文件
- 实现并发。
1) go SpiderPage(url)
2) 创建channel防止主go程退出
3) SpiderPage函数末尾,写入channel
4) 主 go 程 for 读取 channel
代码
package main
import (
"fmt"
"io"
"net/http"
"os"
"regexp"
"strconv"
)
//爬取指定url的页面 返回result
func HttpGet(url string)(result string,err error){
resp,err1 :=http.Get(url)
if err1 !=nil{
err = err1 //将封装函数内部的错误,传出给调用者
return
}
defer resp.Body.Close()
//循环读取网页数据传出给调用者
buf := make([]byte,4096)
for {
n,err2 :=resp.Body.Read(buf)
if n==0{
fmt.Println("读取完成")
break
}
if err2!=nil && err2 != io.EOF{
err = err2
return
}
//累加每一次循环读到的buf数据,存入result一次性返回
result +=string(buf[:n])
}
return
}
func Save2File(idx int,sum,name,introduce [][]string){
Path :="D:/Go code/src/Gopa/07豆瓣纵向多线程/"+"第"+strconv.Itoa(idx)+"页.txt"
f,err :=os.Create(Path)
if err !=nil{
fmt.Println("os.Create err:",err)
return
}
defer f.Close()
n := len(sum) //得到条目数
//打印一个开头
f.WriteString("更新几集"+"\t\t\t"+"电影名称"+"\t\t\t"+"电影介绍"+"\n")
for i :=0;i<n;i++{
f.WriteString(sum[i][1]+"\t\t\t"+name[i+1][1]+"\t\t\t"+introduce[i][1]+"\n")
}
}
//爬取一个页面信息
func SpiderPage(idx int, page chan int){
//获取url地址
url :="https://v.qq.com/channel/cartoon?channel=cartoon&iarea=1&itype="+strconv.Itoa((idx-1)*1)+"&listpage=1&sort=18"
fmt.Println(url)
//封装HttpGet爬取页面
result,err :=HttpGet(url)
if err!=nil{
fmt.Println("HttpGet2 err:",err)
return
}
//fmt.Println("result=",result)
//解析、编译正则表达式--动漫集数
ret1 :=regexp.MustCompile(`<div class="figure_caption" >(?s:(.*?))</div>`)
//提取需要的信息
sum :=ret1.FindAllStringSubmatch(result,-1)
//解析、编译正则表达式--动漫名称
ret2 :=regexp.MustCompile(`target="_blank" title="(?s:(.*?))"`)
//提取需要的信息
name :=ret2.FindAllStringSubmatch(result,-1)
//解析、编译正则表达式--动漫介绍
ret3 :=regexp.MustCompile(`<div class="figure_desc" title="(?s:(.*?))">`)
//提取需要的信息
introduce :=ret3.FindAllStringSubmatch(result,-1)
//读取有用信息传递到参数
Save2File(idx,sum,name,introduce)
//与主go程配合
page <- idx
}
func working(start,end int){
fmt.Printf("正在爬取 %d 到 %d \n",start,end)
page := make(chan int) //防止主go程提前结束
for i:=start;i<=end;i++{
go SpiderPage(i,page)
}
for i:=start;i<=end;i++{
fmt.Printf("第 %d 页爬取完毕\n",<-page)
}
}
func main() {
//指定爬取起始、终止页
var start,end int
fmt.Println("请输入爬取的起始页(>=1):")
fmt.Scan(&start)
fmt.Println("请输入爬取的终止页(>=start):")
fmt.Scan(&end)
working(start,end)
}
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 时间海!


评论





